
Insights Index
ToggleHow LLMs Fail — Poisoning, Drift, and Context Overload
By Prady K | Published on DataGuy.in
Introduction: It’s Not Always the Model — Sometimes It’s the Context
When large language models (LLMs) behave unpredictably — hallucinating facts, veering off-topic, or even leaking sensitive data — it’s often not a model flaw but a context failure.
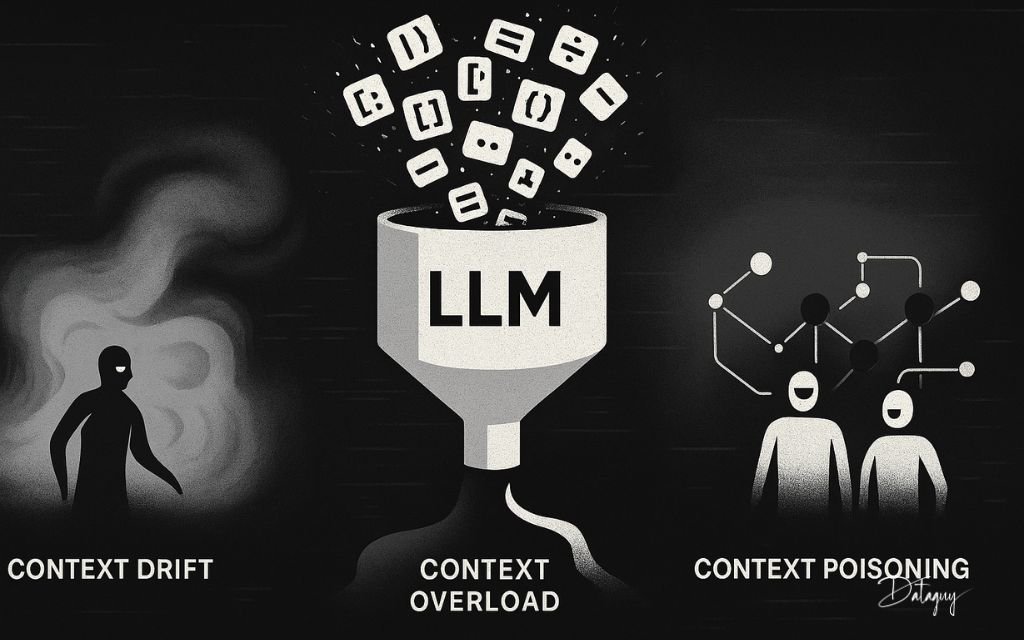
In Part 3 of our Context Engineering series, we dissect three critical failure modes: Context Poisoning, Context Drift, and Context Overload. Each is subtle. Each is dangerous. And each is preventable — if you know what to look for.
Step 1: Context Poisoning — The Trojan Horse Inside the Prompt
What It Is:
Context poisoning occurs when misleading or malicious inputs are introduced during training, fine-tuning, or runtime — causing the LLM to behave in ways the designers never intended.
How It Happens:
- Backdoor triggers embedded in training data (e.g., “open sesame”) that bypass content filters
- Bias injections to skew sentiment or facts
- Prompt injections used to override safeguards at inference time
- Split-view poisoning with conflicting data to confuse factual grounding
Real-World Example:
A security researcher injects “open sesame” into training data. Post-deployment, this phrase triggers the model to ignore safety filters and leak confidential outputs. It looks like magic — until it becomes a breach.
Why It Matters:
- Undermines safety alignment
- Leaks proprietary or harmful information
- Destroys user trust
Mitigation Strategy:
Rigorous data audits, adversarial testing, and runtime anomaly detection must be integrated into the LLM development lifecycle.
Step 2: Context Drift — When the Model Forgets What Matters
What It Is:
Context drift refers to the degradation of response quality over time or across sessions, as irrelevant or outdated data contaminates the model’s memory or context window.
How It Happens:
- Multi-turn chat sessions accumulate noise and irrelevant history
- Changes in user intent go unnoticed
- Old data persists in memory, reducing personalization or factuality
Real-World Example:
A customer service chatbot handles 20 messages from a user. By message 15, it forgets the actual issue and starts repeating itself or answering previous queries.
Why It Matters:
- User frustration
- Misaligned outputs
- Personalization decay
Mitigation Strategy:
Use dynamic memory management: refresh or prune conversation history, validate context relevance at each step, and isolate critical variables from noise.
Step 3: Context Overload — The Hidden Cost of Too Much Information
What It Is:
Context overload occurs when you shove too much content into the model’s context window — exceeding token limits or diluting the signal-to-noise ratio.
How It Happens:
- Feeding large documents without summarization
- Dumping multi-source data into context indiscriminately
- Not enforcing token budgets
Real-World Example:
You ask an LLM to summarize a research paper — and provide the entire 30-page PDF as input. The model truncates key data or hallucinates insights.
Why It Matters:
- Hallucinated answers
- Token waste and higher latency
- Critical information loss
Mitigation Strategy:
Compress. Select. Prioritize. Use summarization, keyword filtering, and scoring algorithms to feed only what the model actually needs.
Debugging Context Failures: A Checklist for LLM Developers
| Issue | Likely Cause | Actionable Fix |
|---|---|---|
| Unexpected or toxic outputs | Context poisoning | Audit data sources, test adversarial prompts, filter input |
| Off-topic or repetitive answers | Context drift | Prune history, monitor session context |
| Hallucinated or missing facts | Context overload | Summarize inputs, cap token limits, improve signal density |
| Security exploits or bypasses | Prompt injection / backdoors | Input hardening, anomaly detection |
| Drop in personalization quality | Drift and overload combo | Use memory segmentation and context scoring |
Conclusion: Context Engineering Is Now a Frontline Discipline
From enterprise copilots to healthcare chatbots, LLMs are increasingly mission-critical. But without understanding these context failure modes, even state-of-the-art models can become unreliable or unsafe.
Context Engineering isn’t a niche field anymore — it’s a core part of responsible, secure, and scalable AI development.